House data set
1978년에 해리슨과 루빈펠드가 수집한 보스턴 교외 지역의 주택 정보
CRIM: 도시의 인당 범죄율
ZN: 2만 5,000 평방 피트가 넘는 주택 비율
INDUS: 도시에서 소매 업종이 아닌 지역 비율
CHAS: 찰스 강 인접 여부(강 주변=1, 그 외=0)
NOX: 일산화질소 농도(10ppm)
RM: 주택의 평균 방 개수
AGE: 1940년 이전에 지어진 자가 주택 비율
DIS: 다섯 개의 보스턴 고용 센터까지 가중치가 적용된 거리
RAD: 방사형으로 뻗은 고속도로까지 접근성 지수
TAX: 10만 달러당 재산세율
PTRATTIO: 도시의 학생-교사 비율
B: 1000(Bk-0.63)^2, 여기서 Bk는 도시의 아프리카계 미국인 비율
LSTAT: 저소득 계층의 비율
MEDV: 자가 주택의 중간 가격(1,000 달러 단위)
import pandas as pd
df=pd.read_csv('https://raw.githubusercontent.com/rickiepark/python-machine-learning-book-3rd-edition/master/ch10/housing.data.txt',header=None, sep='\s+')
df.columns=['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'OTRATIO', 'B', 'LSTAT', 'MEDV']
df.head()
CRIM ZN INDUS CHAS NOX ... TAX OTRATIO B LSTAT MEDV
0 0.00632 18.0 2.31 0 0.538 ... 296.0 15.3 396.90 4.98 24.0
1 0.02731 0.0 7.07 0 0.469 ... 242.0 17.8 396.90 9.14 21.6
2 0.02729 0.0 7.07 0 0.469 ... 242.0 17.8 392.83 4.03 34.7
3 0.03237 0.0 2.18 0 0.458 ... 222.0 18.7 394.63 2.94 33.4
4 0.06905 0.0 2.18 0 0.458 ... 222.0 18.7 396.90 5.33 36.2
[5 rows x 14 columns]
탐색적 데이터 분석(Exploratory Data Analysis, EDA)
EDA 그래픽 도구는 이상치를 감지하고 데이터 분포를 시각화하거나 특성 간의 관계를 나타내는데 도움이 된다.
산점도 행렬(scatterplot matrix)
MLxtend
머신 러닝과 데이터 과학 애플리케이션에서 편리하게 사용할 수 있는 다양한 함수를 제공
pip3 install mlxtendimport matplotlib.pyplot as plt
from mlxtend.plotting import scatterplotmatrix
cols=['LSTAT', 'INDUS', 'NOX', 'RM', 'MEDV']
scatterplotmatrix(df[cols].values, figsize=(10, 8), names=cols, alpha=0.5)
plt.tight_layout()
plt.show()
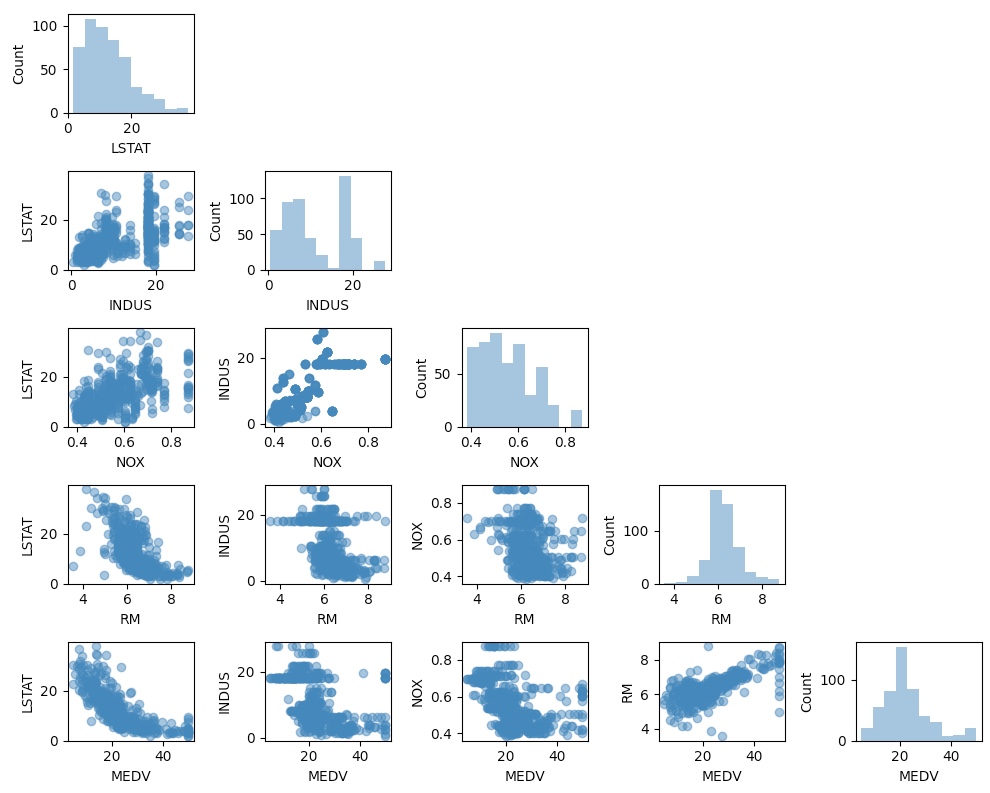
산점도 행렬은 데이터셋에 있는 특성 간의 관계를 시각적으로 잘 요약해 준다.
RM과 MEDV 사이에 선형적인 관계가 있다는 것을 알 수 있다.
또한 MEDV 히스토그램이 정규분포와 유사한 형태를 띠고 있음을 알 수 있다.
선형 회귀의 정규 분포 가정
선형 회귀 모델을 훈련할 때, 특성과 타깃이 정규 분포일 필요는 없다.
정규 분포 가정은 특정 통계와 가설 검증에 필요하다.
상관관계 행렬(Correlation matrix)
상관 관계 행렬은 공분산 행렬(covariance matrix)와 밀접하게 연관이 있다.
공분산 행렬을 스케일 조정한 행렬을 상관관계 행렬로 볼 수 있다.
상관관계 행렬은 피어슨의 상관 계수(Pearson product-moment correlation coefficient)를 포함하고 있는
정방 행렬이다.
피어슨 상관관계 계수(Pearson product-moment correlation coefficient)
특성 사이의 선형 의존성을 측정한다.
상관관계 계수의 범위는 -1 ~ 1로 r=1이면 두 특성이 완벽한 양의 상관관계를, r=0이면 상관관계가 없음을, r=-1이면 완벽한 음의
상관관계를 가진다.
피어슨 상관관계 계수는 단순히 두 특성 x와 y 사이의 공분산(분자)을 표준편차의 곱(분모)으로 나눈 것이다.
r = sigma(x,y)/{ sigma(x)Xsigma(y) }
피어슨 상관관계를 풀어쓰면 표준화된 특성의 공분산과 같다.
머신러닝교과서with파이썬,사이킷런,텐서플로_개정3판pg.410
from mlxtend.plotting import heatmap
import numpy as np
cm=np.corrcoef(df[cols].values.T)
hm=heatmap(cm, row_names=cols, column_names=cols)
plt.show()

상관관계 행렬은 선형 상관관계를 바탕으로 특성을 선택하는데 유용한 정보를 요약해 준다.
선형 회귀 모델을 훈련하려면 타깃 변수 MEDV와 상관관계가 높은 특성이 좋다.
MEDV와 LSTAT가 상관관계가 높다(-0.74) 하지만 산점도 행렬에서 보면, 두 변수가 비선형이다.
MEDV와 RM은 상당히 높은 상관관계(0.7)을 가지고 있으며, 산점도 행렬에서 선형 관계를 가짐을 알 수 있다.
타깃 변수와 상관관계가 높으면서, 산점도 행렬 또한 선형적인 것이 좋다.